
半導体メーカーのNVIDIAが12月12~13日に開催した技術イベント「GTC Japan 2017」において、NVIDIA Global Head - Solutions Architecture & Engineering, Autonomous Drivingのプラディープ・クマール・グプタ氏が登壇し、自動運転車における深層学習の運用体制について解説した。
「80年代からディープラーニングが始まっているが、ここ2~3年でAIビッグバンが起き大きく進展した。膨大なデータ量や処理能力の向上が背景にある。ディープラーニングによってソフトウェア開発そのものが変化した」
グプタ氏は、自動運転を実現するためのAIについて、エキスパートの立場から提言した。
「自動運転の実現を考えると、未知のケースに対応するAIでなければならず、ルールベースは適さない。そして将来的にはAI自身が学び、次のバージョンを開発していくという未来を想定しなければならない。そしてAIは今後も伸展する。そこにはGPUの必要性がある。自動運転車は産業グレードのディープラーニングの活用例となる。それを実現するプラットフォームが必要だ」
そしてグプタ氏は、自動運転のAIの運用における考慮すべき点と運用サイクルついて述べた。
「自動運転車にディープラーニングを利用する際に考慮すべき点は、第一に安全性。これは最優先事項だ。第二にデータ量。センサーも多くなっていくので、とてつもないデータ量となる。これはトレーニングタイムも非常に長くなることを意味する。データ量と、ディープラーニングにかかる学習時間も考慮すべきだ」
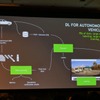
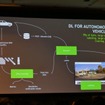
「自動運転のAIの運用は、モデルづくり・トレーニング・データ最適化・デプロイというサイクルを回すことになる。そしてこれは、新しいデータから未知のシーンを取り込んで何度も繰り返す。ディープラーニングが対処できなかったデータだけを抜き出して再学習させ、クルマに投入する手法もある。アクティブラーニングと言われている」
「クルマにデプロイされたモデルは推論を始める。ディープラーニングは自動運転車を現実にするために欠かせないものだ。そしてトレーニング、再トレーニングを繰り返して自動的にデプロイする。このように、自動車のソフトウェアのライフサイクル全体を管理することは、どうしても考えなければならない課題だ。
「この実現にはプラットフォームが必要だろう。まずデータのファイルサイクルの管理だ。データを集め、ラベリングし、管理ができるプラットフォーム。さらにディープラーニングの最適化ができるプラットフォーム。データの収集は続き、それで学習を担保する。そして学習済みのデータでをデプロイできるプラットフォームだ」
グプタ氏のプレゼンテーションは、ことディープラーニングとなるとチップスペックに目が行きがちだが、認知判断を担うエッジ側だけでなく、判断のためのモデルを継続的に進化させ、確実にエッジに配信することができる仕組みづくりの重要性を説いた。
その重要性は、ソフトウェアが複雑になるほど重みを増す。
「チップスペックだけではなくソフトウェア全体が重要だ。ソフトが複雑になり、どんどん変わっていく。自動車はいま、ソフトウェアデファインドカーに踏み込んだところだ。アルゴリズムにしろニューラルネットワークにしろ、ひとつのことに捕らわれると変化に乗り遅れる」
「NVIDIAは、フレキシブルなGPUやツール群を提供する。今後、あらたなニューラルネットワークが出現しないとも言えない。つまりプログラマビリティが重要ということであり、ソフトウェアを固定してしまうのはデメリットになりうる」